Machine Learning¶
Machine Learning is getting a central part of our field. There is a huge curated list with all kinds of ML frameworks and packages
The most recent advances can be found with paper and code on paperswithcode
Online Courses¶
Articles¶
- Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning focusses on classification problems but still is a great resource of how to perform performance evaluations (regarding multiple testing remember the probability for type-1 error for multiple testing is \(1-(1-\alpha)^n\), where \(n\) is the number of test and \(\alpha\) the type-1 error rate of the single test).
- A high-bias, low-variance introduction to Machine Learning for physicists is a nice introduction to core ML techniques.
Books¶
Python Packages¶
shap : Shapely values are a nice way to bring interpretability to Machine Learning. The intepretable machine learning book gives an overview over this and other methods for interpretable ML
holoviews
pandas profiling gives some more useful information for exploratory data analysis than
df.describe()feature selector is a useful package for intial steps of feature engineering
If you already have (ASE) trajectories around, then AMP can be nice to build a ML model based on them
QML has a similar goal. It has efficient implementations to calculate representations and kernels
matminer is really useful to compute common descriptors
Edward is a nice package for probabilistic modelling like bayesian neural nets.
PyMC3 is a popular package for probabilistic programming
missingno is a nice package for analzying missing data
pyGAM is a python implementation of generalized additive models (a nice overview of GAMs is in a blogpost from Kim Larsen)
eli5 is a nice package visualize the explanations of mostely white-box models.
i like to cycle my learning rates . Related is the great idea of snapshot ensembles I hope to find time at some point to generalize the keras implemtation a bit more. This blogpost gives a great overview https://www.jeremyjordan.me/nn-learning-rate/
something that I starting using way to late is tensorboard, in keras it is simply this callback
tbCallBack = keras.callbacks.TensorBoard(log_dir='logs', histogram_freq=0, write_graph=True, write_images=True)
followed by
tensorboard --logdir logs
to actually start tensorboard.
Magpie is not only a brid but also a ML framework for inorganic materials
PyOD contains loads of different tools for outlier detection
Various trivia¶
An underappreciated measure of centreal tendency is the trimean (\(TM\))
\[TM = \frac{Q_1 + 2Q_1 + Q_3}{4},\]where \(QM_2\) is the median and \(Q_1\) and \(Q_2\) are the quartiles.
“An advantage of the trimean as a measure of the center (of a distribution) is that it combines the median’s emphasis on center values with the midhinge’s attention to the extremes.” — Herbert F. Weisberg, Central Tendency and Variability.
It is quite useful to keep the following nomogram in mind
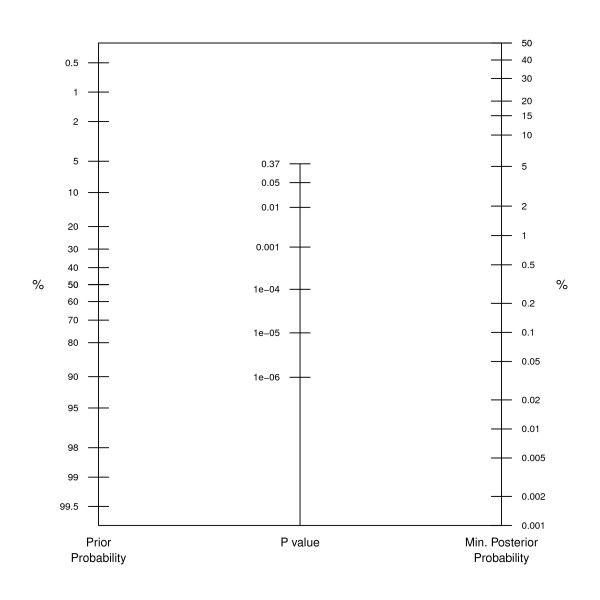
- This is directly connected to
“Extraordinary claims require extraordinary evidence” – Carl Sagan/Laplace
A nice visualization of the famous Ioannidis paper is this RShiny app
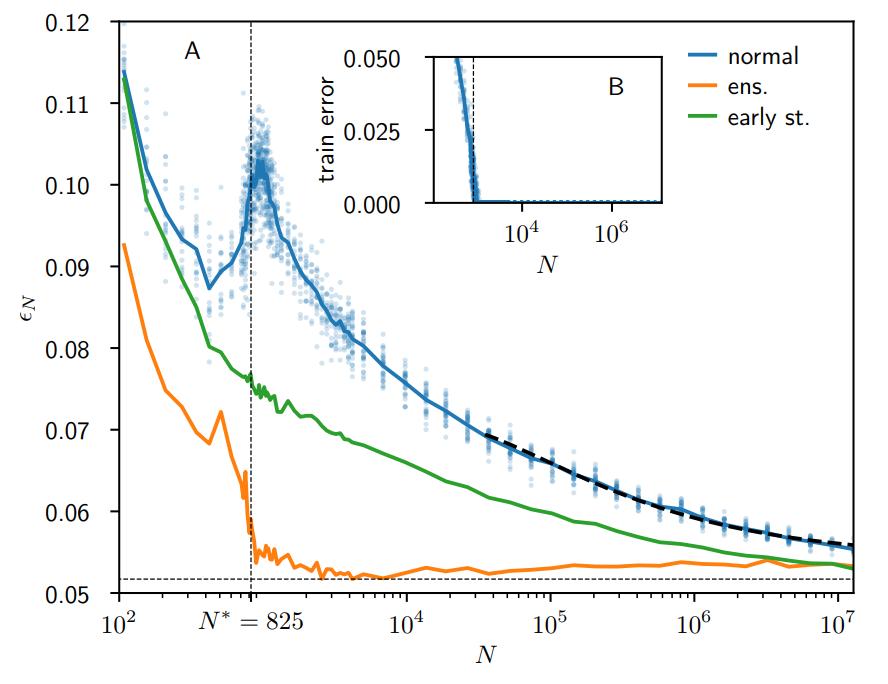
A quite interesting discussion of the variance in the output function is reduced by adding more parameters to a (ensembled) network which then leads to a lower generalization error. They also provide a discussion of a divergence of the error at \(N^*\) for networks without regularization. Preprint version is on arXiv:1901.01608v3
I find dilated convolutional NNs to be quite a interesting way to increase the perceptive field. Ferenc Huszár gives another description in terms of Kronecker factorizations of smaller kernels
Spatial dropout is quite interesting to make dropout work better on spatial correlations.
Jensen’s paper about GA for logP optimization and also a recent work from Berend Smit’s group are reminders that we shouldn’t forget good old techniques such as GA.
{kind=link}